
ChatGPT などの AI が世の中を賑わせています。今回は、ChatGPTの話ではなく、AIで画像を生成するお話です。Midjourney というサービスをご存知でしょうか。情報としては遅いくらいなので、ご存知の方も多いと思いますが、2022年7月ごろに始まった、テキストからAIで画像を生成するサービスです。このサービスは、Discord を使う必要があり、無料版では世界中の人が自分がオーダした画像を見る(保存する)ことができてしまいます。また、無料で利用できるのは25回までという制限もついています。自分のローカルPCで画像生成することができれば一番うれしいですね。ということで、今回はそんな要望に応えられる、Stable Diffusion を紹介します。
※ 以下の情報は 2023.03.13 日時点の情報です。この界隈の更新速度はかなり早いようなので、情報が古くなっているかもしれません。
Stable Diffusion
Stable Diffusion (ステーブルディフュージョン)は、Stability AIがオープンソースで公開した、ディープラーニング(深層学習)によって入力したテキストから画像を自動作成することができるAIです。このソースコードも、2022年8月ごろに初公開されました。当初は、動作環境に高級なGPUがないと動かないとか、コマンドライン操作に詳しくないと環境が整えられないなどの問題もあったようですが、いまでは有志の方が作成したソフトで環境作成がとても簡単になっています。
その中でもお勧めなのが、AUTOMATIC1111 氏が開発された、stable-diffusion-webui が導入が容易でお勧めです。
本家(StabilityAI社):
https://github.com/Stability-AI/stablediffusion
stable-diffusion-webui(AUTOMATIC1111氏):
https://github.com/AUTOMATIC1111/stable-diffusion-webui
事前準備
StableDiffusion(stable-diffusion-webuiも)は、Pythonで動いているため、Pythonを導入します。AUTOMATIC1111氏のgitを見ると、現在は 3.10.6が必須要件のようですので、これに従って入れてください。

インストールの仕方は過去の記事を参考にバージョンを読み替えてください。

また、自動でgitにアクセスして必要なソースコードを取得してくるため、gitもインストールする必要があります。(gitの使い方は知らなくても大丈夫です。)

stable-diffusion-webui の導入(GPU 4G以上)
- 前述の Webサイト(Git)へアクセスして、Code>Download ZIP でOKです。
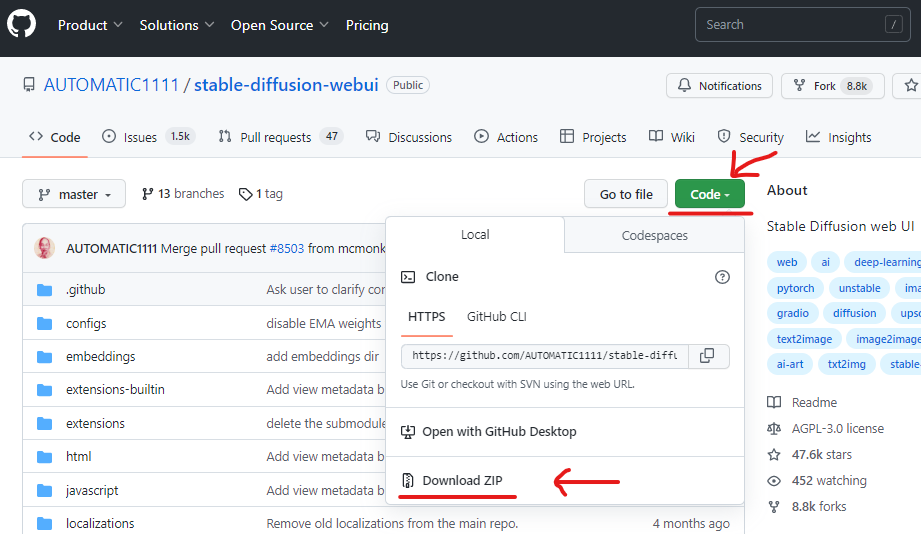
- ダウンロードが済んだら、適当なところに解凍します。この後、自動セットアップで大量のファイルがダウンロードされます(5-10GB くらいのディスクの開きを見ておきましょう)。
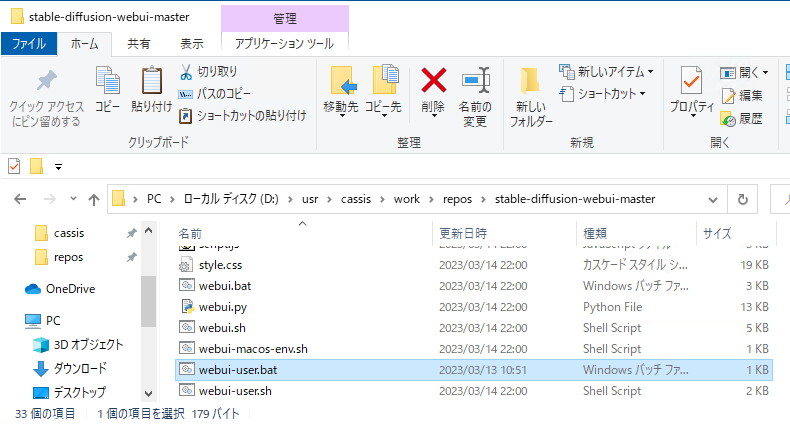
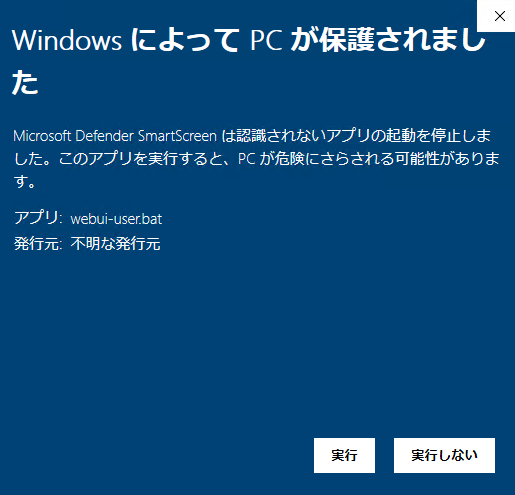
- 解凍が済んだら、中にある「webui-user.bat」をダブルクリックします。ネットからダウンロードしたものとして、警告画面が出る場合がありますが、使いたい場合には「許可」します(※自己責任です)。
- コマンドプロンプトが立ち上がり、ダウンロードとセットアップが開始されます。
- 以下のようにコマンドプロンプトに「Running on local URL: http://127.0.0.1:7860」と出力されれば、成功しています。
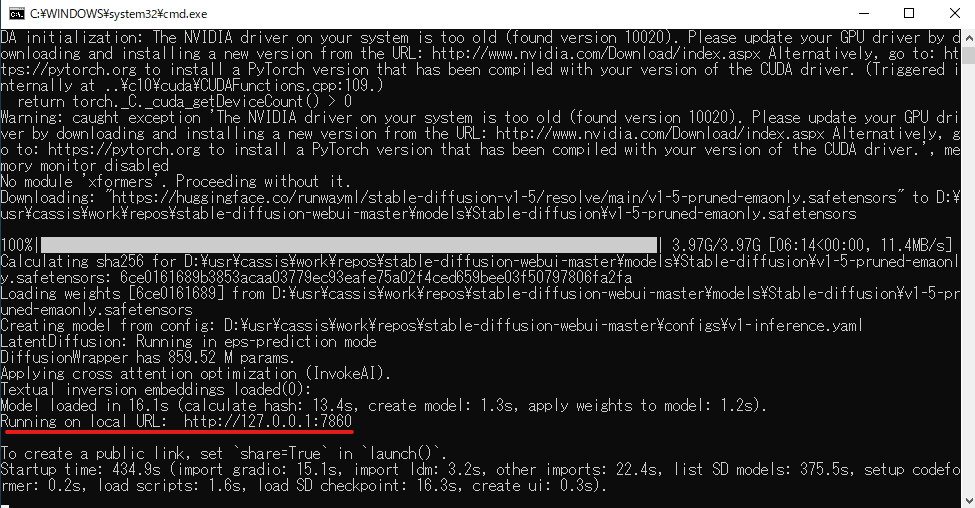 (※ 画像は、CPUモードでの起動です。torch や cuda のダウンロード&ビルドがなかったので早く終わっています。=特にわからなくても大丈夫です。)
(※ 画像は、CPUモードでの起動です。torch や cuda のダウンロード&ビルドがなかったので早く終わっています。=特にわからなくても大丈夫です。)
※ git の readme.md の動作要件から、GPUのメモリが最低でも2-4GBは必要とのことです。我が家にはGPUメモリ 4GBのものと、GPUメモリ1Gのものがありますが、GPUメモリ1Gの方はCPUモードでしか動かせませんでした。
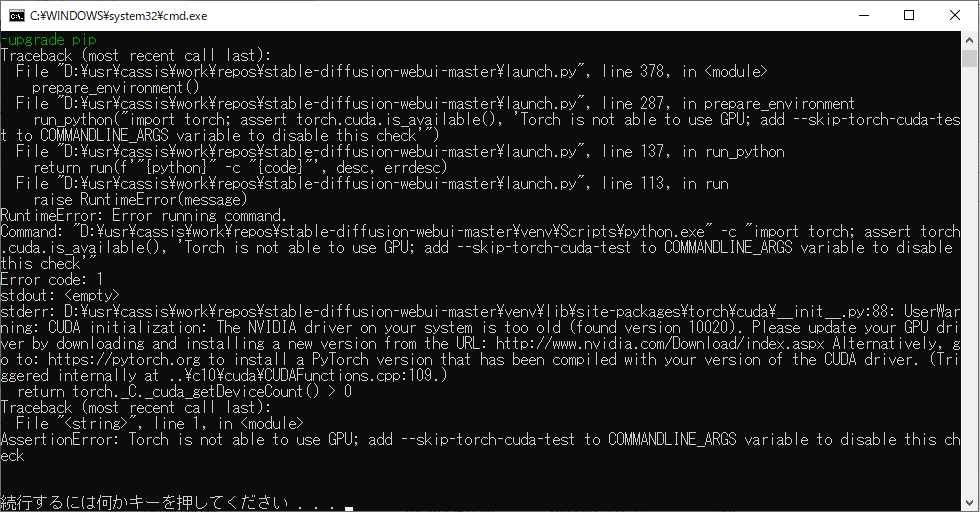
CPU モードで動かすオプション(GPUなし/GPUメモリ不足)
bat が、エラーでセットアップがうまく行かない場合は、一度コマンドプロンプトを閉じて、「webui-user.bat」をエディタで開き、COMMANDLINE_ARGS に 以下を追加します。
こんな感じになります。エディタを保存して、再度実行してみましょう。

stable-diffusion-webui を使おう
コマンドプロンプトに、出力されている http://127.0.0.1:7860 にブラウザでアクセスします。こんな感じで、web画面が出力されます。下にはいろいろパラメータはありますが、ひとまずデフォルト(なにもいじらず)で、矢印のところに、「cat,asleep」といれて、「generate」ボタンを押します。
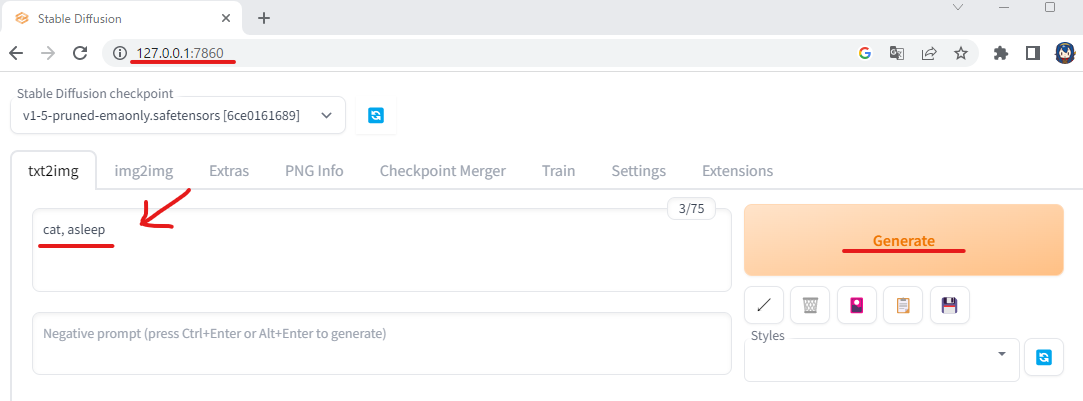
こんな画像が生成されました。「generate」ボタンを押すたびに、違う画像が生成されます。

次回は、各パラメータをいじってみたいと思います。
最後に
CPUモードはとにかく時間がかかります。今回の検証では1枚の画像を生成するのに、5分~6分程度かかりました。ひとまず、触ってみたい人にはいいと思いますが、たくさん生成するのには少し時間がかかりすぎです。(※ 気に入った奇跡の一枚を探すためには複数生成する必要があるみたいです。)
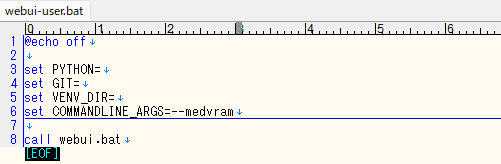
また、GPUのメモリが4G程度(我が家の最高峰マシン)の場合、生成はCPUよりかなり早く(1分程度)出来ましたが、画像生成中にエラーで落ちることがあります。そういった場合は、一度コマンドプロンプトを閉じて、「webui-user.bat」をエディタで開き、COMMANDLINE_ARGS に 以下を追加するとよいです。(※ stable-diffusion-webui の wiki より)
こんな感じになります。エディタを保存して、再度実行してみましょう。
参考:
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Optimizations
12Gのメモリを積んだGPUを買おうとすると、5万円は余裕でいくので、なかなか購入するにはハードルが高いですね。
ただ、AIが実際に動いているところを見てみると、「もっと早く生成してみたい!」なんて思ってしまい、購入を検討してしまいそうになります。
コメント