
前回はとりあえず、Python で作った Alexa スキルを使って Echo dot で Google Drive 上の mp3の音楽を流せることを確認しました。今回は、複数のmp3を再生するためにプレイリストを用います。あらかじめ用意したプレイリストを順に再生するようにします。
前回の記事はこちら

以下で、JSONの扱い方を事前に検証していますのでよければ参考にしてください。

参考:

事前準備
プレイリストの準備
プレイリストの一覧(playlists)と、それに紐づく音源のリスト(playlist)を以下のような感じで用意します。アルファベットの文字列は、ファイルIDに置き換えます。(すべてのリソースはURL共有されている必要があります。)
プレイリストの一覧(playlists)の ファイルID を控えて、プログラムへ反映します。
プレイリストの一覧(playlists)の中身(例:
"playlists": {
"favorite": "AAAAABBBBBCCCCC",
"drive": "DDDDDEEEEEFFFFF",
"relax": "GGGGGHHHHHIIIII",
"sleep": "JJJJJKKKKKLLLLL"
}
}
曲のリスト(playlist)の中身(例:
{ "id": "MMMMMNNNNNOOOOO", "info": "Title1"},
{ "id": "PPPPPQQQQQRRRRR", "info": "Title2"},
{ "id": "SSSSSTTTTTUUUUU", "info": "Title3"},
{ "id": "VVVVVWWWWWXXXXXX", "info": "Title4"}
]
スロットタイプの準備
左側のメニューから「アセット>スロットタイプ」を選択し、「+スロットタイプ」をクリックします。
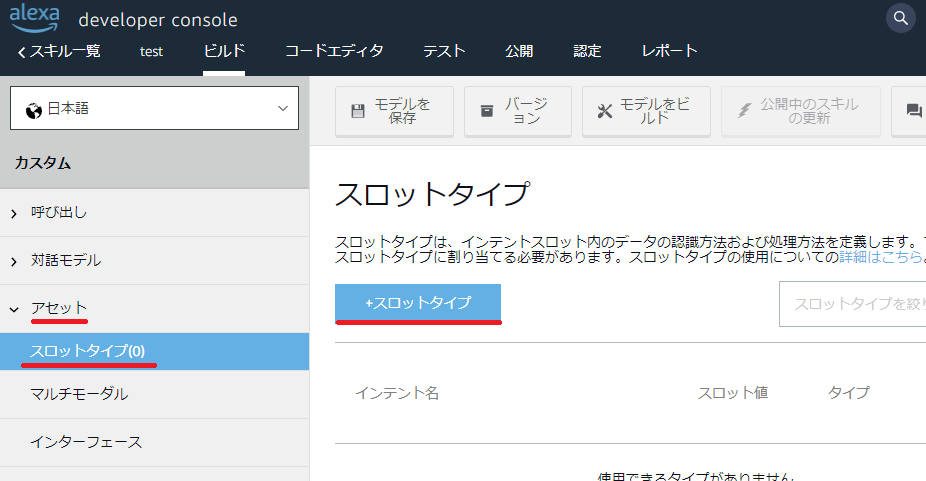
「値を持つカスタムスロットタイプを作成」を選択し、「playlist」と名付け、「次へ」をクリックします。
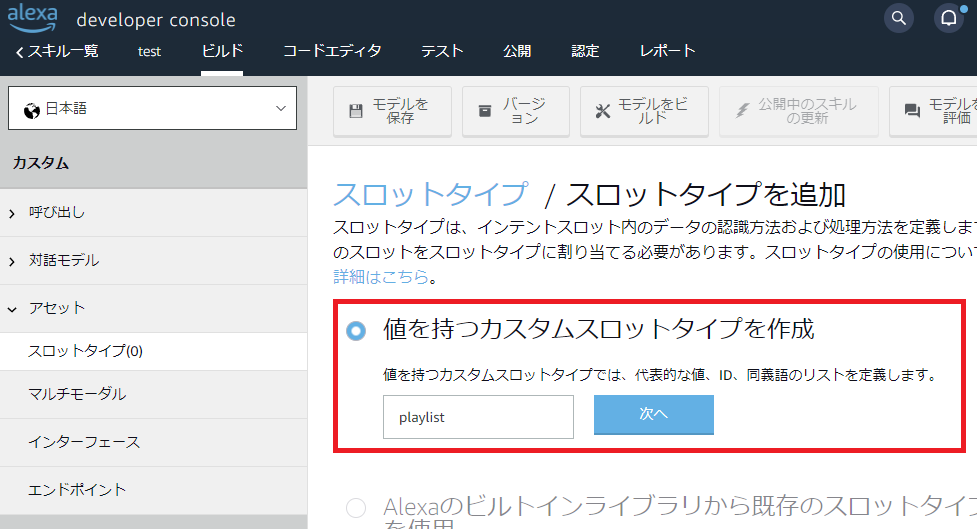
値にユーザーが指定するプレイリスト名を入力し、IDに「playlists」に記載した「キー」を入力します。一度、「モデルを保存」をクリックしておきます。これで「発話」→「キー(ID)」→「playlistのファイルID」が取得できるようになります。
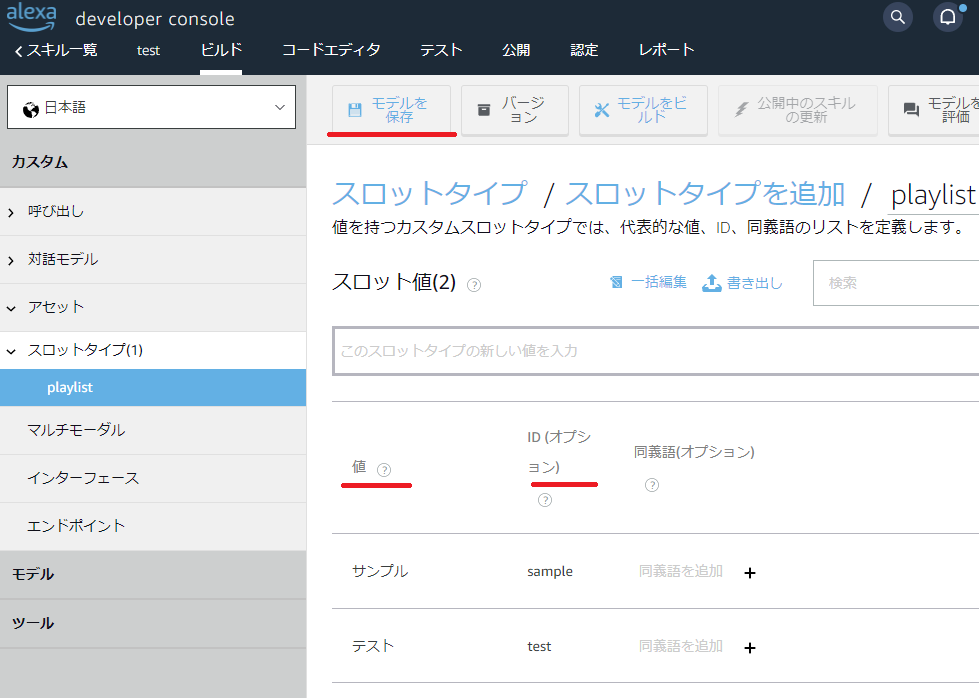
インテント
左側のメニューから「対話モデル>インテント」を選択します。HelloWorldIntent を削除し、「+インテントを追加」をクリックします。
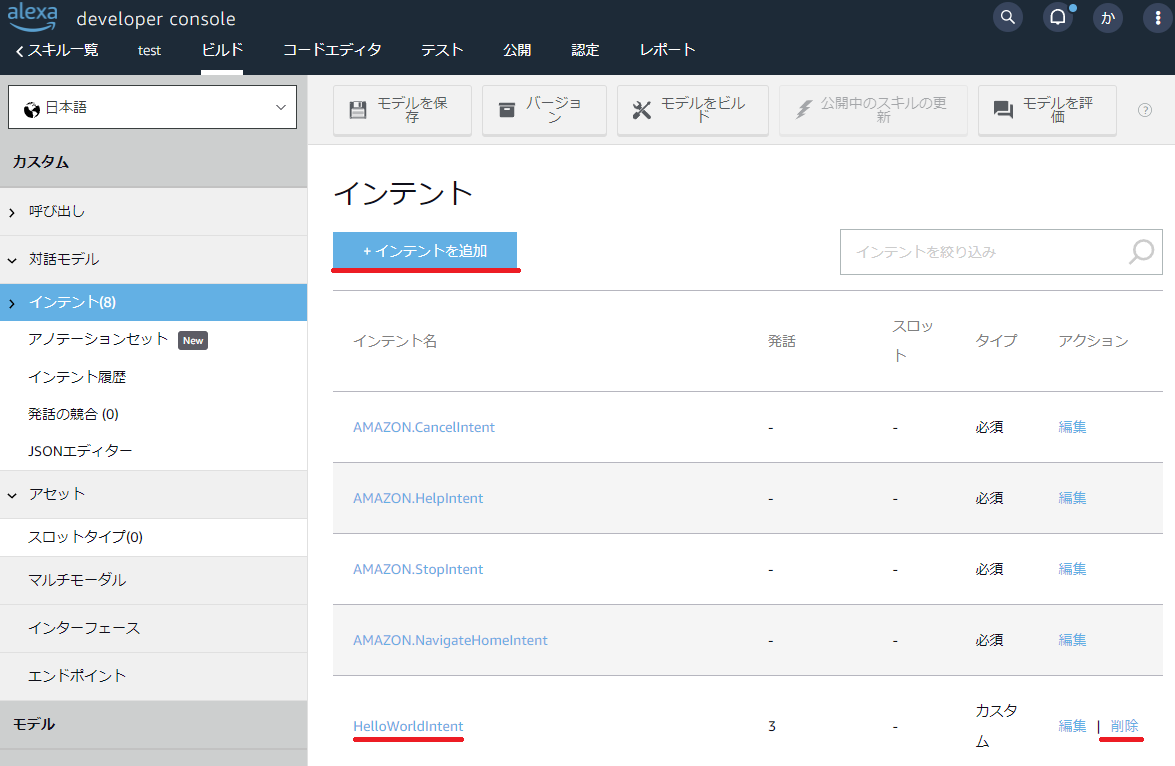
「カスタムインテントを作成」を選び、「PlayIntent」と入力し「カスタムインテント作成」をクリックします。

「サンプル発話」に「{playlist} を再生」や「{playlist}」と入力します。インテントスロットに playlist が追加されますので、「スロットタイプ」に先ほど準備したplaylistを入力します。
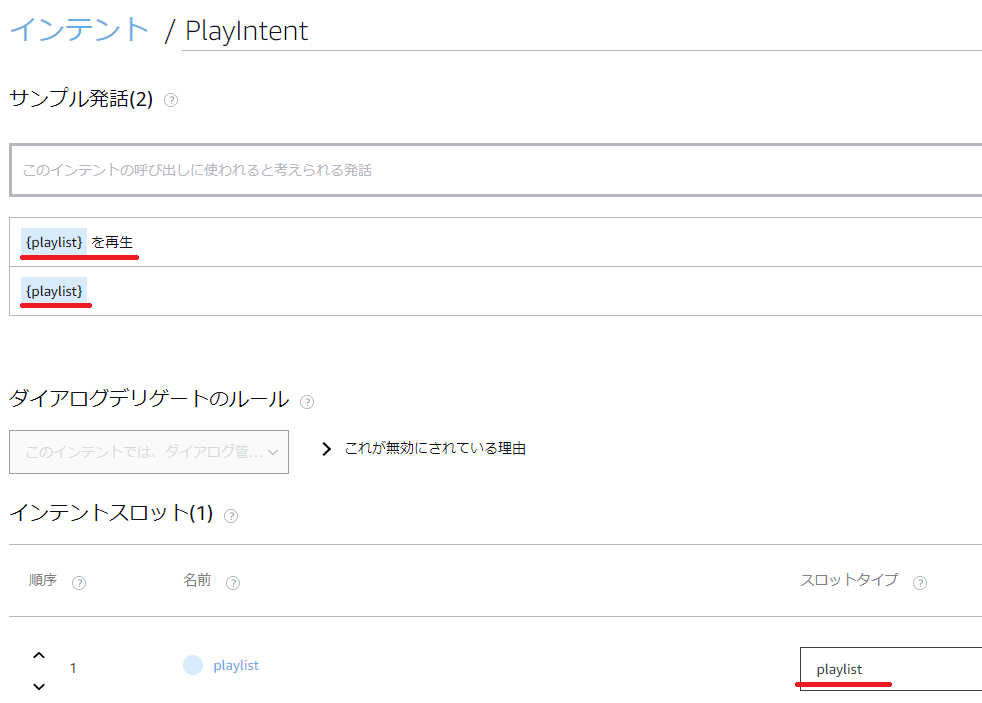
最後に、「モデルを保存」をクリックし、「モデルをビルド」をクリックします。
ソースコード
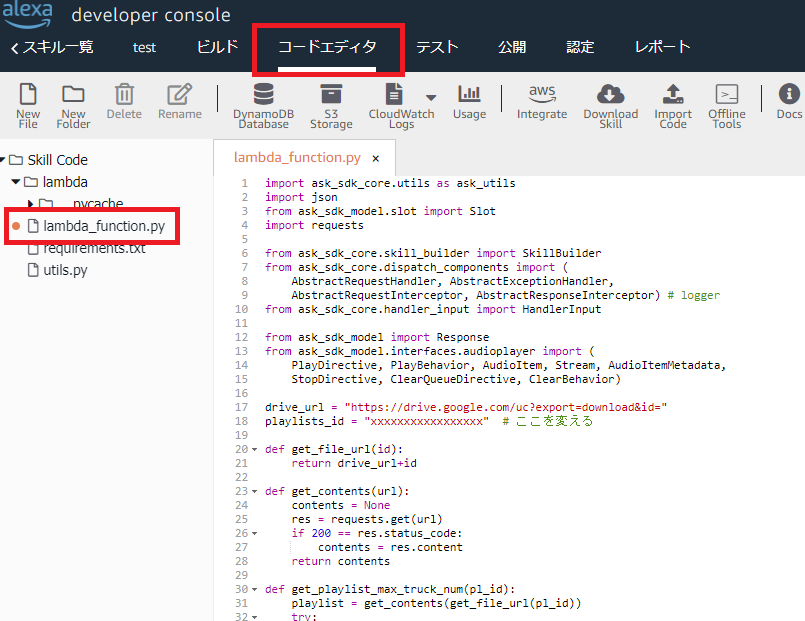
コードエディタを開き、以下のソースコードを張り付けます。plyalists_id を準備した「playlists」の ファイルIDに置き換えてください。
「保存」をクリック後、「デプロイ」をクリックします。
ソースコード
今回は抜粋ではなく、全ソースコードを張り付けます。playlists_id を自身のGoogleDriveに配置したプレイリストの一覧(playlists)の fileId に変更すれば動作すると思います。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 | import ask_sdk_core.utils as ask_utils import json from ask_sdk_model.slot import Slot import requests from ask_sdk_core.skill_builder import SkillBuilder from ask_sdk_core.dispatch_components import ( AbstractRequestHandler, AbstractExceptionHandler, AbstractRequestInterceptor, AbstractResponseInterceptor) # logger from ask_sdk_core.handler_input import HandlerInput from ask_sdk_model import Response from ask_sdk_model.interfaces.audioplayer import ( PlayDirective, PlayBehavior, AudioItem, Stream, AudioItemMetadata, StopDirective, ClearQueueDirective, ClearBehavior) drive_url = "https://drive.google.com/uc?export=download&id=" playlists_id = "xxxxxxxxxxxxxxxxx" # ここを変える def get_file_url(id): return drive_url+id def get_contents(url): contents = None res = requests.get(url) if 200 == res.status_code: contents = res.content return contents def get_playlist_max_truck_num(pl_id): playlist = get_contents(get_file_url(pl_id)) try: dc = json.loads(playlist) max_truck = len(dc) except: max_truck = 0 return max_truck def get_playlist_id(key): id = None playlists = get_contents(get_file_url(playlists_id)) try: dc = json.loads(playlists) id = dc['playlists'][key] max_truck = get_playlist_max_truck_num(id) except: id = None return id, max_truck def get_slot_id(slot): id = None try: id = slot.resolutions.resolutions_per_authority[0].values[0].value.id except: id = None return id def get_sound_source_id(pl_id, truck_num): playlist = get_contents(get_file_url(pl_id)) try: dc = json.loads(playlist) id = dc[truck_num]['id'] info = dc[truck_num]['info'] except: id=None info=None return id,info def play(url, offset, token, response_builder): response_builder.add_directive( PlayDirective( play_behavior=PlayBehavior.REPLACE_ALL, audio_item=AudioItem( stream=Stream( token=token, url=url, offset_in_milliseconds=offset, expected_previous_token=None), metadata=None ) ) ).set_should_end_session(True) return response_builder.response def play_later(url, token , response_builder): response_builder.add_directive( PlayDirective( play_behavior=PlayBehavior.REPLACE_ENQUEUED, audio_item=AudioItem( stream=Stream( token=token, url=url, offset_in_milliseconds=0, expected_previous_token=None), metadata=None)) ).set_should_end_session(True) return response_builder.response def stop(text, response_builder): response_builder.add_directive(StopDirective()) if text: response_builder.speak(text) return response_builder.response def make_token(pl_id, truck_num, max_truck): token = pl_id + ":" + truck_num + ":" + max_truck return token def split_token(token): [pl_id, truck_num, max_truck] = token.split(':') return pl_id, truck_num, max_truck def get_next_truck(truck_num, max_truck): next = int(truck_num) + 1 if next >= int(max_truck) : truck_num = 0 else: truck_num = next return str(truck_num) class LaunchRequestHandler(AbstractRequestHandler): def can_handle(self, handler_input): return ask_utils.is_request_type("LaunchRequest")(handler_input) def handle(self, handler_input): speak_output = "どのプレイリストを再生しますか?" return ( handler_input.response_builder .speak(speak_output) .ask(speak_output) .response ) class PlayHandler(AbstractRequestHandler): def can_handle(self, handler_input): return ask_utils.is_intent_name("PlayIntent")(handler_input) def handle(self, handler_input): pl_id = None truck_num = 0 slot = ask_utils.get_slot(handler_input, slot_name="playlist") key = get_slot_id(slot) if key != None: pl_id, max_truck = get_playlist_id(key) if pl_id == None or max_truck == 0: speak_output = "プレイリストを認識できませんでした。もう一度お願いします。" if pl_id != None: sound_id,sound_info = get_sound_source_id(pl_id, truck_num) sound_url = get_file_url(sound_id) token = make_token(pl_id, "0" , str(max_truck)) return play(url=sound_url,offset=0,token=token,response_builder=handler_input.response_builder) return ( handler_input.response_builder .speak(speak_output) .ask(speak_output) .response ) class PlaybackNearlyFinishedHandler(AbstractRequestHandler): def can_handle(self, handler_input): return ask_utils.is_request_type("AudioPlayer.PlaybackNearlyFinished")(handler_input) def handle(self, handler_input): token = handler_input.request_envelope.request.token [pl_id, truck_num, max_truck] = token.split(':') truck_num = get_next_truck(truck_num, max_truck) sound_id,sound_info = get_sound_source_id(pl_id, int(truck_num)) sound_url = get_file_url(sound_id) token = make_token(pl_id, truck_num , max_truck) return play_later( url=sound_url, token=token, response_builder=handler_input.response_builder) class PreviousIntentHandler(AbstractRequestHandler): def can_handle(self, handler_input): return (ask_utils.is_intent_name("AMAZON.PreviousIntent")(handler_input) or ask_utils.is_request_type("PlaybackController.PreviousCommandIssued")(handler_input)) def handle(self, handler_input): speak_output = "その操作には、まだ対応していません。" return ( handler_input.response_builder .speak(speak_output) .response ) class NextIntentHandler(AbstractRequestHandler): def can_handle(self, handler_input): return (ask_utils.is_intent_name("AMAZON.NextIntent")(handler_input) or ask_utils.is_request_type("PlaybackController.NextCommandIssued")(handler_input)) def handle(self, handler_input): speak_output = "その操作には、まだ対応していません。" return ( handler_input.response_builder .speak(speak_output) .response ) class PlaybackStoppedHandler(AbstractRequestHandler): def can_handle(self, handler_input): return ask_utils.is_request_type("AudioPlayer.PlaybackStopped")(handler_input) def handle(self, handler_input): return handler_input.response_builder.response class HelpIntentHandler(AbstractRequestHandler): def can_handle(self, handler_input): return ask_utils.is_intent_name("AMAZON.HelpIntent")(handler_input) def handle(self, handler_input): speak_output = "You can say hello to me! How can I help?" return ( handler_input.response_builder .speak(speak_output) .ask(speak_output) .response ) class CancelOrStopIntentHandler(AbstractRequestHandler): def can_handle(self, handler_input): return (ask_utils.is_intent_name("AMAZON.CancelIntent")(handler_input) or ask_utils.is_intent_name("AMAZON.StopIntent")(handler_input) or ask_utils.is_intent_name("AMAZON.PauseIntent")(handler_input) ) def handle(self, handler_input): speak_output = "再生を停止します" return stop(speak_output, handler_input.response_builder) class StartOverIntentHandler(AbstractRequestHandler): def can_handle(self, handler_input): return (ask_utils.is_intent_name("AMAZON.StartOverIntent")(handler_input) or ask_utils.is_intent_name("AMAZON.LoopOnIntent")(handler_input) or ask_utils.is_intent_name("AMAZON.LoopOffIntent")(handler_input) or ask_utils.is_intent_name("AMAZON.ShuffleOnIntent")(handler_input) or ask_utils.is_intent_name("AMAZON.ShuffleOffIntent")(handler_input) or ask_utils.is_intent_name("AMAZON.ResumeIntent")(handler_input)) def handle(self, handler_input): speak_output = "その操作には対応していません。" return ( handler_input.response_builder .speak(speak_output) .response ) class SessionEndedRequestHandler(AbstractRequestHandler): def can_handle(self, handler_input): return ask_utils.is_request_type("SessionEndedRequest")(handler_input) def handle(self, handler_input): return handler_input.response_builder.response class IntentReflectorHandler(AbstractRequestHandler): def can_handle(self, handler_input): return ask_utils.is_request_type("IntentRequest")(handler_input) def handle(self, handler_input): intent_name = ask_utils.get_intent_name(handler_input) speak_output = "You just triggered " + intent_name + "." return ( handler_input.response_builder .speak(speak_output) .response ) class CatchAllExceptionHandler(AbstractExceptionHandler): def can_handle(self, handler_input, exception): return True def handle(self, handler_input, exception): speak_output = "エラーが発生しました。" return ( handler_input.response_builder .speak(speak_output) .ask(speak_output) .response ) sb = SkillBuilder() sb.add_request_handler(LaunchRequestHandler()) sb.add_request_handler(PlayHandler()) sb.add_request_handler(PreviousIntentHandler()) sb.add_request_handler(NextIntentHandler()) sb.add_request_handler(PlaybackNearlyFinishedHandler()) sb.add_request_handler(PlaybackStoppedHandler()) sb.add_request_handler(StartOverIntentHandler()) sb.add_request_handler(HelpIntentHandler()) sb.add_request_handler(CancelOrStopIntentHandler()) sb.add_request_handler(SessionEndedRequestHandler()) sb.add_request_handler(IntentReflectorHandler()) # make sure IntentReflectorHandler is last so it doesn't override your custom intent handlers sb.add_exception_handler(CatchAllExceptionHandler()) lambda_handler = sb.lambda_handler() |
シミュレーターでは、MP3は再生されないので注意

Unsupported Directive
AudioPlayer is currently an unsuppored namespace. Check the device log for more information.
前回も書きましたが、スキルシミュレータで動作を確認しようとすると、シミュレータの右下に、上の様なエラーが出てきます。シミュレータでは Audio の再生は行われないようで、実機が必要になります。Alexa 端末を持っていない人は、スマホに Alexa アプリを入れて開発のアカウントでログインすると、開発中の「スキルテスト」が呼び出せます。
コメント